- YouTube
www.youtube.com
오토핫키로 OCR(광학 문자 인식,Optical character recognition )을 구현하려는 노력을 훌륭한 분들이 이미 많이 해 놓으셨습니다. 그중에서도 Tesseract의 경우 현재는 구글이 운영하고 있는데 훌륭한 인식률을 제공합니다. 저희는 그것을 가져다 쓰면 됩니다. Tesseract lib는 다양한 언어를 제공하는데, Autohotkey용은 iseahound라는 아이디를 가진 분이 제공한 것이 좋은듯 합니다. 아래 링크에서 다운로드 받으면 됩니다.
git원본 : https://github.com/iseahound/Vis2
귀찮은 분들은 아래 파일을 받으세요.
해당 파일을 다운로드한 후, 원하는 폴더에 압축을 풀면 아주 간단한 구조입니다.

다시 lib와 bin폴더로 나뉘어져 있고, 아래 화면에서 우측은 lib폴더의 내용이고, 중간의 내용은 bin폴더의 내용입니다.
결국 우리가 사용할 예제는 demo.ahk와 lib안의 4개 ahk파일입니다.

demo.ahk를 열어 보면 구조가 단순합니다.
#include <Vis2> ; Equivalent to #include .\lib\Vis2.ahk
Vis2.Graphics.Subtitle.Render("Press [Win] + [c] to highlight and copy anything on-screen.", "time: 30000 xCenter y92% p1.35% cFFB1AC r8", "c000000 s2.23%")
tr := Vis2.Graphics.Subtitle.Render("Processing test.jpg... Please wait", "xCenter y67% p1.35% c88EAB6 r8", "s2.23% cBlack")
MsgBox % text := OCR("test.jpg")
tr.Destroy()
#c:: OCR() ; OCR to clipboard
#i:: ImageIdentify() ; Label images
#1:: MsgBox % OCR("https://i.stack.imgur.com/sFPWe.png")
Esc:: ExitApp
#include <Vis2>는 주석대로 #include .\lib\Vis2.ahk와 같습니다.
다음 2줄은 화면상에 "Press...부터 내용을 표시해 줍니다.
Vis2.Graphics.Subtitle.Render("Press [Win] + [c] to highlight and copy anything on-screen.", "time: 30000 xCenter y92% p1.35% cFFB1AC r8", "c000000 s2.23%")
아래는 실행 결과입니다.

그리고 현재 폴더아래에 있는 test.jpg파일을 인자로 OCR()를 수행하여 그 결과를 text 에 넣어 주고 그 내용을 msgbox로 표시해 줍니다. 실제로 test.jpg파일의 내용은 아래와 같습니다.

아래는 메시지박스로 나온 결과입니다.

내용이 정확합니다.
그리고 나서 사용자가 Win+c를 누를 경우 화면 중간 하단에 아래처럼 창이 뜹니다.

그리고 원하는 영역을 마우스로 드래그해서 잡아 주면 해당 내용을 읽어서 메시지창으로 보여줍니다.
여기서 소스 코드 일부를 잡아 봤습니다.

다음으로 win+i를 눌러 보면 역시 이미지 영역을 클릭할 수 있고, 이어서 아래창이 뜨는데 저는 해당 api_key가 없어서 멈추었습니다.

다음은 github에 있는 설명대로 예제 소스를 복사해서 넣었습니다. 키는 win+1로 할당했고, 저자가 해당 사이트에 올려놓은 그림을 읽어서 내용을 메시지 박스로 띄워 주는 내용입니다. 실제 해당 사이트는 아래와 같습니다.

실제로 win+1을 눌러서 결과를 확인합니다.
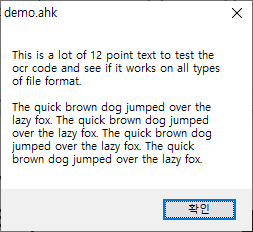
내용이 동일함을 알 수 있습니다.
2) 한글 및 기타 다른 언어 인식하기
추가로 영어 이외의 언어에 대한 지원을 원할 경우 아래처럼 사전 작업이 필요합니다.
우선 best본과 fast본 2가지 버전중에서 필요한 버전을 받으면 됩니다.
git원본(best본) : https://github.com/tesseract-ocr/tessdata_best
git원본(fast본) : https://github.com/tesseract-ocr/tessdata_fast
해당 언어만 다운로드 받을 경우 해당 언어만 받아도 됩니다. 저희는 시험삼아 한국어(kor.traineddata ), 일본어 (jpn.traineddata ), 중국어( chi_sim.traineddata , chi_tra.traineddata )를 시험해 보겠습니다. 해당 언어에 _vert가 붙은 버전도 있는데 시험해 본 결과 인식이 달라서 해당 용도가 따로 있는듯 합니다. 이 언어들의 사이즈가 제법 큽니다. 특히나 best의 경우 사이즈가 더 크므로 좀 더 많은 데이터가 있는 것으로 판단됩니다. 대신 인식하는데 시간은 더 오래 걸립니다. fast를 적용할 경우에는 인식은 빨리 하지만 오류가 발생할 수 있습니다.
사전 작업이 끝났으므로 실제로 읽어올 이미지를 만들어 보겠습니다. 영어, 한글, 한자, 일본어등을 구분하기 몇가지 파일을 만들었습니다.
먼저 영어만 있는 내용인데, 폰트 사이즈를 7부터 다양하게 넣었습니다.

영어와 한글이 있는 내용인데, 폰트 사이즈를 7부터 다양하게 넣었습니다.

다음으로 중국어, 한글, 일본어를 넣은 파일입니다.

다음은 가나다를 다양한 각도로 회전시킨 이미지입니다.

이제 실제로 읽어오도록 OCR(0를 부르면 되는데 2번째 인자에 해당 언어를 넣어 주면 됩니다. 원하는 언어파일의 확장자를 제외한 이름을 명기해 주면 됩니다. 예를 들어 한글의 경우 파일 이름이 kor.traineddata 이므로 "kor"로 주면 되고, 중국어 번체의 경우 "chi_tra"로 주면 되며, 만약 영어와 일본어를 동시에 할 경우, "eng+jpn"으로 하면 됩니다.
#2:: MsgBox % OCR("abc.png","kor+eng")
#3:: MsgBox % OCR("abconly.png","kor+eng")
#4:: MsgBox % OCR("ganada.png","kor+eng")
#5:: MsgBox % OCR("chjpko.png","chi_tra+jpn+kor+eng")
#6:: MsgBox % OCR("chjpko.png","chi_tra+jpn+kor_vert+eng")
#7:: MsgBox % OCR("chjpko.png","chi_tra")
#8:: MsgBox % OCR("chjpko.png","chi_tra_vert")
#9:: MsgBox % OCR("chjpko.png","chi_sim")
다양한 옵션을 넣고 진행해 본 결과, 언어는 가급적 1개씩 넣는게 인식률도 좋고, 판정하는 시간도 짧습니다. 만약 언어를 여러개 선택하면 그만큼 오래 걸립니다. 그리고 중국어만 지정할 경우 제대로 인식하나, 다른 언어와 같이 인식하려고 하면 중국어는 잘 인식이 되지 않았고, 다른 언어만 인식이 잘 되었습니다. 또한 chi_tra기준으로 입력된 내용을 chi_sim 으로 읽으라고 하면 잘못 읽는 경우가 많았습니다. 참고하시어 진행하시면 되겠습니다.
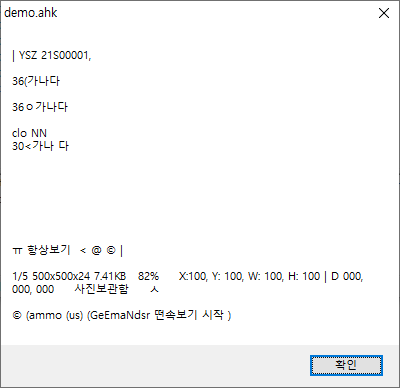
win+2결과 : 실행파일로 진행하느냐? 디버그로 진행하느냐에 따라 결과가 다를 수 있습니다. 그 이유는 아직 찾지 못 했습니다.
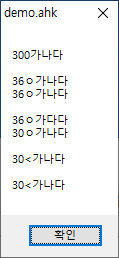
win+3결과 :
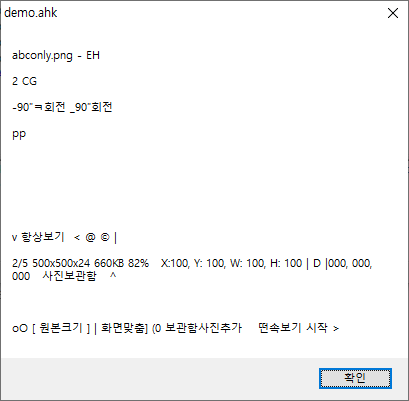
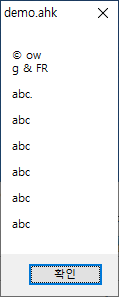
win+4결과 :
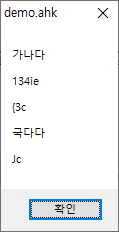
win+5결과 :
한자만 제대로 인식이 안 되었습니다.
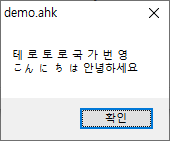
win+6결과 :
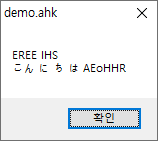
한자, 한글이 제대로 인식이 안 되었습니다.
win+7결과 :
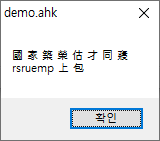
한자는 제대로 인식되고, 한글/일본어가 제대로 인식이 안 되었습니다.
win+8결과 :
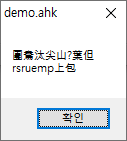
한자/한글/일본어가 제대로 인식이 안 되었습니다.
win+9결과 :
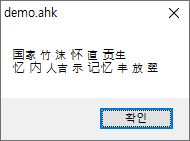
한자/한글/일본어가 제대로 인식되지 않었습니다.
결론적으로 정확한 언어로 설정하는게 가장 좋은 결과를 나타낸다고 보시면 되겠습니다.
Tesseract OCR이 무료인데다 인식률이 좋아서 어떤 특정 분야에 사용하려고 판단하시는 분들도 계실텐데, 오늘 제가 다양한 삽질을 해 봤으므로 해당 결과를 토대로 판단하시면 되겠습니다.
아래는 해당 스크립트입니다.
추가로 별도의 내용을 원하는게 있을 경우 댓글 남겨 주시면 검토해 보겠습니다.
'Autohotkey강좌' 카테고리의 다른 글
| 엑셀 vba로 다중 vlookup 구현하기-동일한 항목 전체 찾기 (4) | 2022.05.01 |
|---|---|
| 데이터 변경되면 자동으로 실행하는 엑셀 매크로 (0) | 2022.03.21 |
| Autohotkey#49, 고정IP/유동IP Setting 자동화 (0) | 2022.02.21 |
| Autohotkey#48, ControlSend와 SetTitleMatchMode (2) | 2022.02.11 |
| Autohotkey #47. Notepad++로 Autohotkey 스크립트 디버깅하기 (0) | 2022.01.29 |



{kind=link}
{kind=link}
{kind=link}